With the release of SQL Server 2016 JSON objects support is now available. With the ever growing popularity and versatility of JSON, including JSON support into SQL Server is good for both database and application developers. In a previous post we looked at how to output a JSON object in a dataset using the FOR XML PATH clause and some string concatenation. This process can be rather difficult to read and updating can be a challenge. In this blog post we are going to use the FOR JSON PATH clause to simplify the JSON building process.
A brief background regarding JSON (JavaScript Object Notation). JSON is a lightweight data interchange format similar to XML, however it is based on specific programing languages such as C and Java. It is a data format that is easily understandable for both humans and machines. JSON is machine and language independent, which makes it a great language for data interchange between different systems. For more information regarding JSON please see the following URL https://www.json.org/json-en.html..
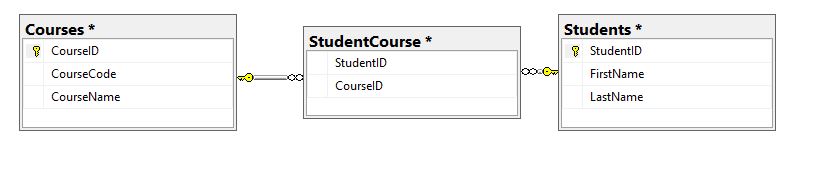
In the previous post our goal was to output the student information with a JSON object that described the courses and grades the student received.
{
"Grades": [{
"CourseCode": "[Course Code]",
"CourseName": "[Course Name]",
"Grade": "[Course Grade]"
}]
} |
In the previous blog post we used some crazy string concatenation to build out the JSON Object. Here is that query, with the string concatenation and using the SUBSTRING function to clean up the excess commas and whitespace.
SELECT s.StudentID , s.FirstName , s.LastName , GradesJSON = '{"Grades":[' + SUBSTRING(( SELECT ', {"CourseCode":"'+ c.CourseCode + '", "CourseName":"' + c.CourseName + '", "Grade":"' + sc.Grade + '"}' FROM #StudentCourse sc JOIN #Courses c ON c.CourseID = sc.CourseID WHERE s.StudentID = sc.StudentID FOR XML PATH('')),3,1000) + ']}' FROM #Students s; |
Using the FOR JSON PATH clause instead of FOR XML PATH clause will simplify our syntax and make our code easier to read and understand. We will still need to output the same columns and use the correlated sub query idea to map the student course/grade data to the proper student in the outer query. The names of the columns will become the data elements in JSON object.
SELECT s.StudentID , s.FirstName , s.LastName , GradesJSON = ( SELECT CourseCode = c.CourseCode , CourseName = c.CourseName , Grade = sc.Grade FROM #StudentCourse sc JOIN #Courses c ON c.CourseID = sc.CourseID WHERE s.StudentID = sc.StudentID FOR JSON PATH ) FROM #Students s WHERE StudentID = 10005; |
| StudentID | FirstName | LastName | Courses |
|---|---|---|---|
| 10005 | Will | Williams | [{“CourseCode”:”ICS140″, “CourseName”:”Introduction to Programming”, “Grade”:”A”}] |
The only thing that is missing in the root grades element, so lets add that in.
SELECT s.StudentID , s.FirstName , s.LastName , GradesJSON = ( SELECT CourseCode = c.CourseCode , CourseName = c.CourseName , Grade = sc.Grade FROM #StudentCourse sc JOIN #Courses c ON c.CourseID = sc.CourseID WHERE s.StudentID = sc.StudentID FOR JSON PATH, ROOT('Grades') ) FROM #Students s WHERE StudentID = 10005; |
| StudentID | FirstName | LastName | Courses |
|---|---|---|---|
| 10005 | Will | Williams | {“Grades”:[{“CourseCode”:”ICS140″, “CourseName”:”Introduction to Programming”, “Grade”:”A”}]} |
There we have it, the same dataset structure including the nested JSON objects without all of the crazy string concatenation and SUBSTRING Function usage. Here is the full script:
DROP TABLE IF EXISTS #Students GO DROP TABLE IF EXISTS #Courses GO DROP TABLE IF EXISTS #StudentCourse GO CREATE TABLE #Students ( StudentID INT PRIMARY KEY NOT NULL , FirstName NVARCHAR(50) NOT NULL , LastName NVARCHAR(50) NOT NULL ) GO CREATE TABLE #Courses ( CourseID INT PRIMARY KEY NOT NULL , CourseCode NVARCHAR(50) NOT NULL , CourseName NVARCHAR(50) NOT NULL ) CREATE TABLE #StudentCourse( StudentID INT NOT NULL , CourseID INT NOT NULL , Grade VARCHAR(5) NULL ) INSERT INTO #Students (StudentID, FirstName, LastName) VALUES (10001, N'Bob',N'Roberts') , (10002, N'John',N'Johnson') , (10003, N'Tom',N'Tompson') , (10004, N'Rich',N'Richardson') , (10005, N'Will',N'Williams'); GO INSERT INTO #Courses ( CourseID , CourseCode , CourseName ) VALUES (140, N'ICS140', N'Introduction to Programming') , (225, N'ICS225', N'Web Programming') , (240, N'ICS240', N'Advanced Programming') , (310, N'ICS310', N'Database Management'); INSERT INTO #StudentCourse (StudentID, CourseID, Grade) VALUES (10001, 140, 'A') , (10001, 225, 'B+') , (10001, 240, 'B-') , (10001, 310, 'B') , (10002, 240, 'C+') , (10002, 310, 'A-') , (10004, 140, 'A') , (10004, 225, 'B') , (10005, 140, 'A'); SELECT s.StudentID , s.FirstName , s.LastName , GradesJSON = ( SELECT CourseCode = c.CourseCode , CourseName = c.CourseName , Grade = sc.Grade FROM #StudentCourse sc JOIN #Courses c ON c.CourseID = sc.CourseID WHERE s.StudentID = sc.StudentID FOR JSON PATH, ROOT('Grades') ) FROM #Students s; |