One feature that I would like to see added to SSIS is the ability to format a date string with a specified format. I have been tasked many times with outputting file names or folders with a specific date format, such as YYYYMMDD, and found myself writing custom functionality to accomplish this task. This is not difficult in T-SQL, but in SSIS it’s not all that easy. In this blog post I am going to show a few ways that we can format a date string into a specific format. I will show how to use an Expression task, SQL task, and a Script task.
Expression Task
EXP – Format Date as YYYMMDD
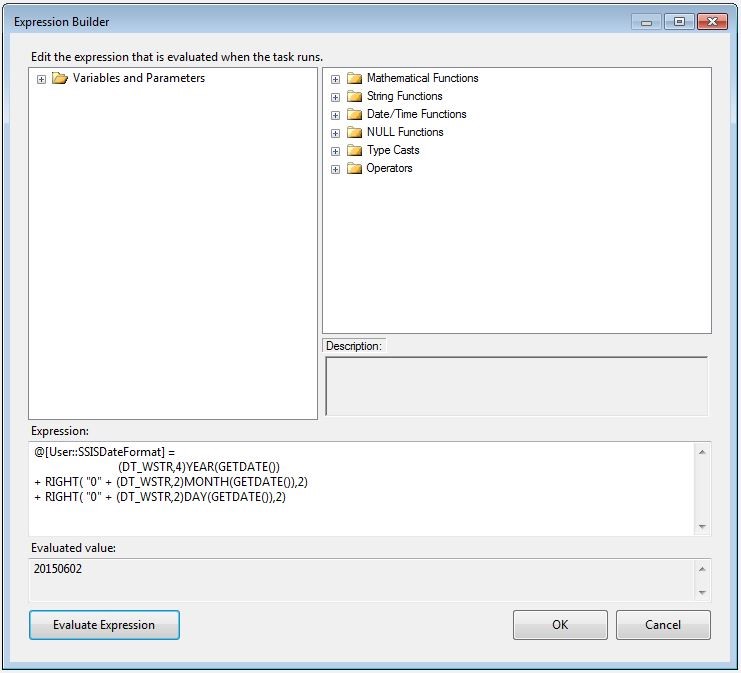
The expression task is a new features with 2012 which allows us to store the result of an expression in a variable. Basically we create an expression using the Expression Builder window and store the result into a SSIS variable. In the windows below you can see an example of the expression being set to the SSISDateFormat variable.
@[User::SSISDateFormat] = (DT_WSTR,4)YEAR(GETDATE()) + RIGHT ( "0" + (DT_WSTR,2)MONTH(GETDATE()),2) + RIGHT ( "0" + (DT_WSTR,2)DAY(GETDATE()),2) |
SQL Task
SQL – Format Date as YYYYMMDD
The SQL Task is a commonly used task in SSIS. This task allows us to execute queries against a data source and return a full result set, a single row, or nothing at all. We also have the opportunity to pass variables into the query as well. However, for this example we will not pass anything in, and only return back a single row. Using T-SQL’s CONVERT function it’s very easy to format a date string. We will use this CONVERT function and return the single row and store the results into a SSIS Variable. The SQL syntax that we will use is:
SELECT SQLDateFormat = CONVERT(NVARCHAR(8),GETDATE(),112); |
Here is a link to additional formats for the CONVERT function. https://technet.microsoft.com/en-us/library/ms187928.aspx
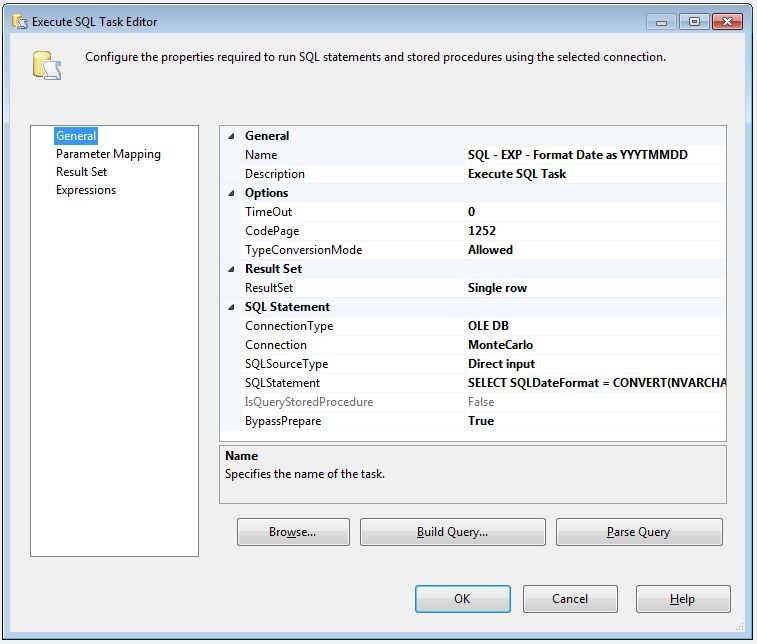
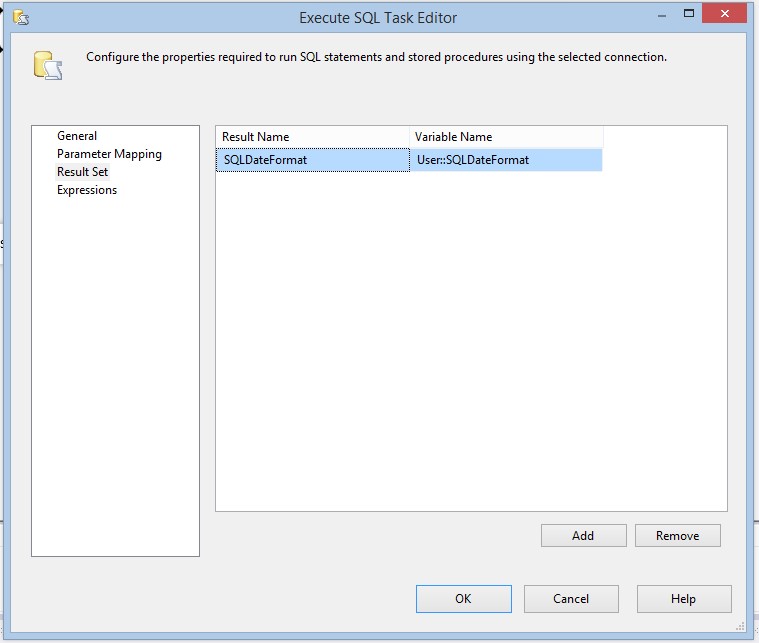
After the SQL Task executes the result will be stored in the SQLDateFormat SSIS variable, which is configured in the window below.
Script Task
SCR – Format Date YYYYMMDD
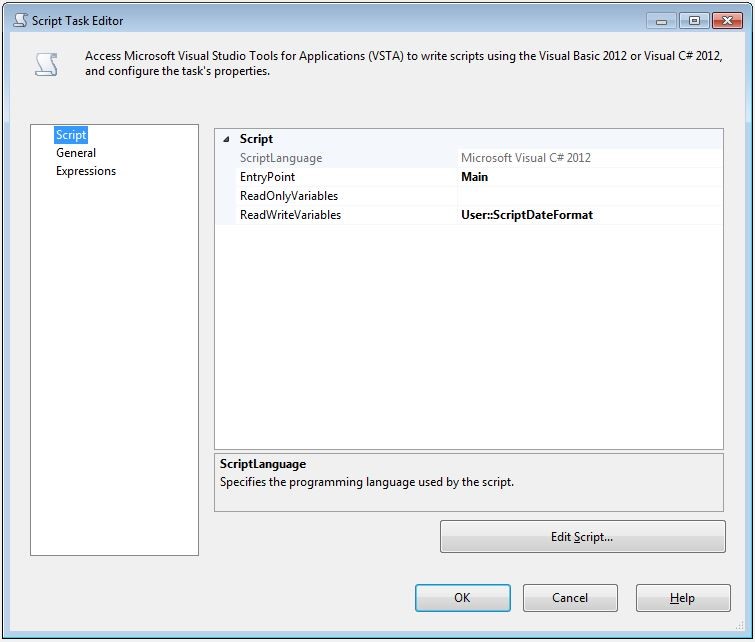
The script task is one of my favorite tasks, mainly because all of the additional functionality that I have access too, but it also gives me an opportunity to play with C#.net code. By passing the SSIS variable ScriptDateFormat into the ReadWriteVariables box, we can access that variable through code. In programming languages like C#.net it’s very easy to format a date string. There is a ToString() method that provides many date formats by using specific characters. When we click on the Edit Script button the Visual Studio for Apps design time environment appears. We can access the ScriptDateFormat variable through the Dts.Variables array and save string values to it. The result of C#.net DateTime.Now.ToString(“yyyyMMdd”) method call will give us a formatted date, this formatted date we can save to our Dts.Variables array. To get a date in T-SQL we use the GETDATE and in C#.net we use DateTime.Now. So the entire line of code would look like this.
Dts.Variables["ScriptDateFormat"].Value = DateTime.Now.ToString("yyyyMMdd"); |
Here is a link to MSDN page that has the format specifiers.
https://msdn.microsoft.com/en-us/library/8kb3ddd4.aspx
Summary
So which is the best way? I personally prefer the Script task, mainly because it’s clean and simple. The Expression Task is a complicated expression, and the SQL Task involves an unnecessary round trip to the server to get a formatted date string. With that said, all three options work and I am sure there are other ways as well.