Well Rick Krueger( blog | @DataOgre ) and I are back at it again. We have decided to pair up and do a talk about a rather controversial topic in the SQL Server community, NoSQL. Now we are not jumping ship and saying that NoSQL is the way of the future, because that is simply not true. Relational databases have been around since the 70′s and still outperform NoSQL Solutions at most tasks. The idea that we are going to seed is that these NoSQL solutions may have a place in enterprise applications. We are not going to say you should use SQL Server or a NoSQL Solution exclusively, rather we are going to claim Polyglot Persistence. Polyglot Persistence is the idea of using multiple data stores to solve multiple problems, hence Rules of Engagement: NoSQL is SQL Server’s Ally. In a previous blog post I discussed Key Value Stores, in this blog post I will be discussing another version of the NoSQL solutions, Column Data Stores.
Column Data Stores
Column Data Stores and Relational Database share some concepts like rows and columns. However, column data stores do not require columns to be defined, nor is space allocated for each column. A column is simply a key value pair, where the key is an identifier and the value stores values related to the key. Columns can be added without all of the overhead that is incurred with a Relational Database. A column can exist for every row, some rows, or only one row. A row can have many different columns or just one. Being that the primary focus of column data stores is the column, performing aggregations or returning column data becomes very fast. The image below depicts a sample column store, with a concept of column families, which are groupings of like column data. This concept of groupings help with more complex queries.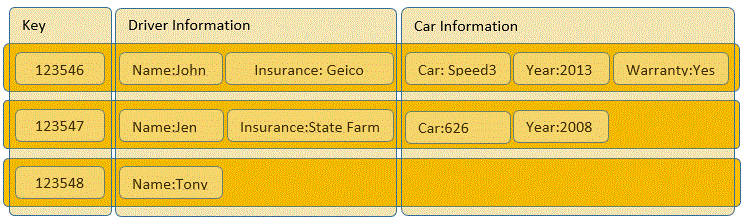 The image above shows a simple example of what a column’s key values could look like, however they can store much more. The columns themselves can store rows and columns. Thinking of this as a table with-in a table would be correct. In a relational database we would use a secondary table linking back to the primary with a foreign key. The example below shows the comparison between a relational model and a column store model.
The image above shows a simple example of what a column’s key values could look like, however they can store much more. The columns themselves can store rows and columns. Thinking of this as a table with-in a table would be correct. In a relational database we would use a secondary table linking back to the primary with a foreign key. The example below shows the comparison between a relational model and a column store model.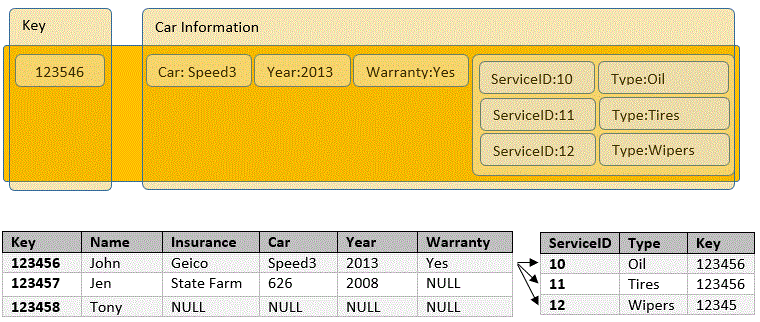 The big advantage here is that we are bringing the related data closer to each other, which makes data retrieval fast. However trying to aggregate this type of data becomes difficult and requires a Map Reduce job.
The big advantage here is that we are bringing the related data closer to each other, which makes data retrieval fast. However trying to aggregate this type of data becomes difficult and requires a Map Reduce job.
Just like the Key Value stores two big benefits to Column Stores are horizontal scaling and the lack of a schema requirement. However, with Column Stores, having a good understanding of the tables and key structure defined prior to development helps implementing a useful data store.
Column Data Stores Implementations
One of the most recognized Column Data Stores comes from the Hadoop world, it’s called HBase. Apache HBase is the database that sits on top of Hadoop and HDFS (Hadoop File System). HBase was designed to handle big data, millions of records with millions of columns type of big data. This is something you should keep in mind when selecting a data store. If you have big data, then looking at a data store solution like HBase is worth the effort. One of the biggest benefits that I have seen is the ability to store all the data that we would normally have to archive in a RDBMS. Here is an example, think of an Automobile company like GM. They have been selling cars and servicing cars for years. This would be big data! In a RDBMS we would have to eventually archive data to keep costs down, however with an HBase solution, we simply add more nodes to the Hadoop cluster and let HDFS work its magic. Imagine being able to go back and getting every service record for a car built in the 50′s, this is what HBase and Hadoop can give you.
Polyglot Persistence, SQL Server and Column Data Stores
An example would be an enterprise application that stores US census data. Here again we have big data. Let’s say the requirements are that we need to store the past 50 years of census data. However only the past 3 years need to be returned in real time, whereas the rest of the data could be returned over time, maybe in a queued report. We could store all 50 years of data in a RDBMS, however that could get rather costly and most likely will impact performance. Rather, we could store the past 3 years in a RDBMS and push the remaining data into a NoSQL solution and scale horizontally as needed. This hybrid data solution is polyglot persistence and best of all solves the problem at hand.
Conclusion
I am not recommending that you re-write your applications to make room for a NoSQL solution, I am simply suggesting that you as the DBA (keeper of data), should keep an open mind to other possibilities. If there is another solution out there that could assist SQL Server, or is maybe a better fit, exploring the avenue might result in a better data solution. As always, a round peg will fit into a square hole if you have a big enough hammer.