There are many common daily tasks that (SSIS) SQL Server Integration Services implements with minimal effort. These tasks can be done by adding a few SSIS tasks, data flows, and containers. In this blog series I am going to explore some of these simple tasks and how I go about implementing them. Looping through a directory of files definitely qualifies as simple task using SSIS. In this blog post I will show how to traverse a set of files and log the files found using SSIS. This blog post builds on a previous Simple SSIS blog post, Importing Data from Flat Text Files
Prerequisites
We will need a database table called FileImport, which will store the file details, for the File Loop SSIS package.
FileImport
The File Import table is the historical logging table. This table contains all of the file details, such as start and end time, if it was imported of if an error occurred, as well as a path to the file.
CREATE TABLE dbo.FileImport ( FileImportID INT IDENTITY(1, 1) NOT NULL , FileName NVARCHAR(1000) NOT NULL , ImportStartDate DATETIME NULL , ImportEndDate DATETIME NULL , RecordCount INT NULL , Imported BIT NULL , ErrorMessage NVARCHAR(MAX) NULL , CONSTRAINT PK_FileImport PRIMARY KEY CLUSTERED (FileImportID ASC) ) ON [PRIMARY]; |
File Loop SSIS package
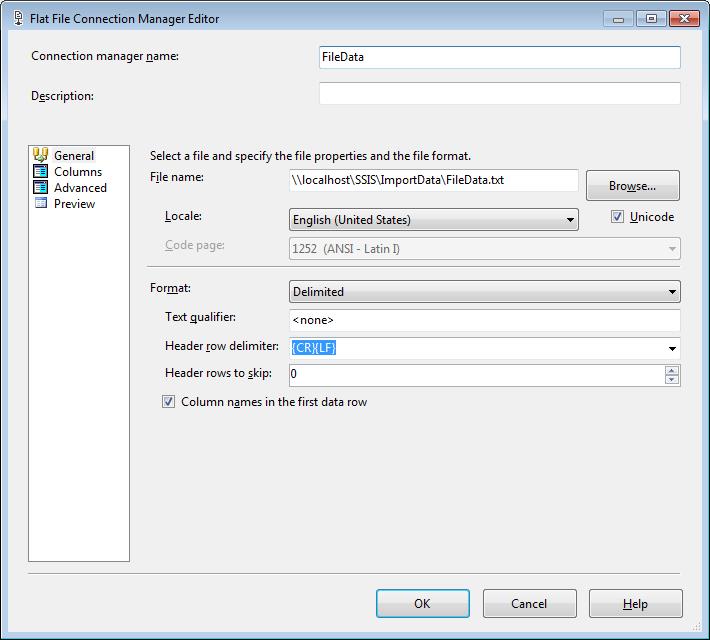
The File Loop SSIS package will traverse a specified folder capturing the path of each file stored in the folder. For each file, we will write some basic file details to a log table and import data from the file into a file details table. The details of the file import is left to a previous Simple SSIS blog post.
Let’s start by creating a new SSIS Package and renaming it to FileLoop.dtsx. The package will need a couple variables which are defined below.

Variable Definitions
- The ImportFolder is the folder where all of the files to be imported are stored.
- The ImportPath is the actual path to each file. This will be updated on each iteration of the foreach loop container.
Package Tasks
The File Loop package will use a Foreach Loop Container, an Execute SQL Task, and a Data Flow Task.
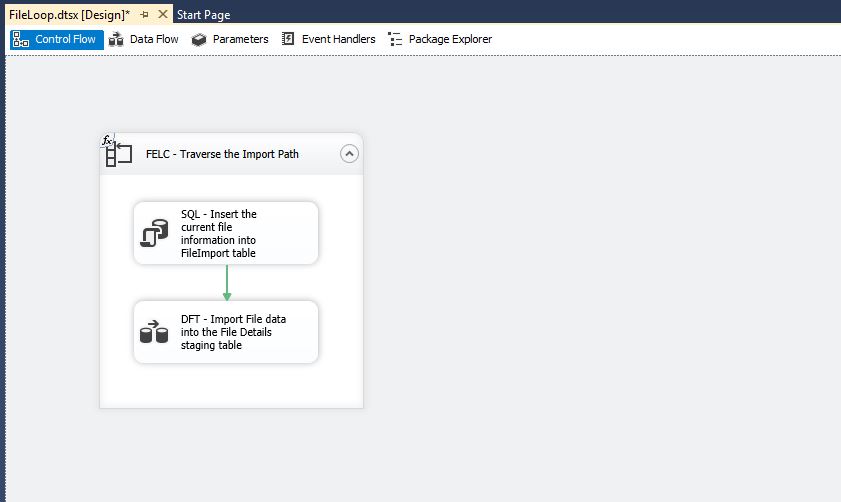
FELC – Traverse the Import Path
This Foreach Loop Container will traverse the list of files that are stored in the designated folder. Using an expression we can dynamically set the Directory/Folder at runtime. For this import we are only looking for files that start with FileData and have a .txt extension. We will want the fully qualified path to the file and do not want to traverse the sub folders.
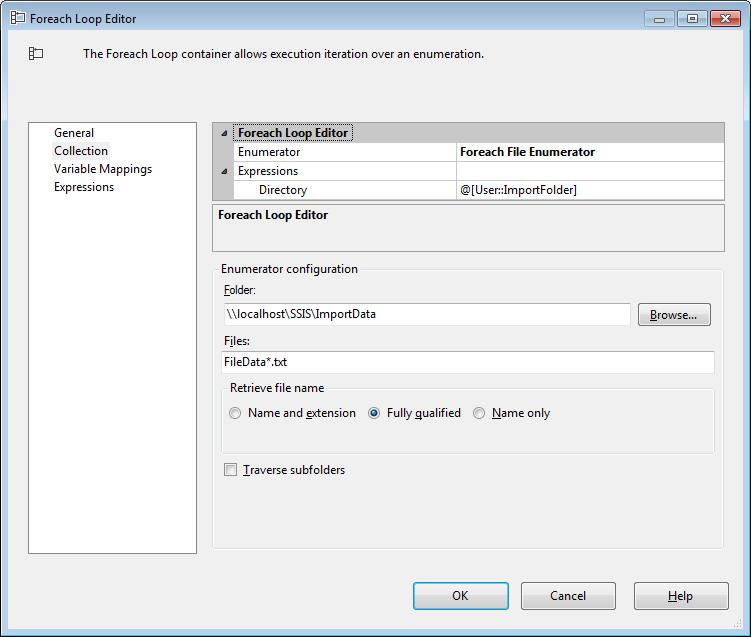
On each iteration of the loop we will save the path to each of the files in the ImportPath SSIS variable.
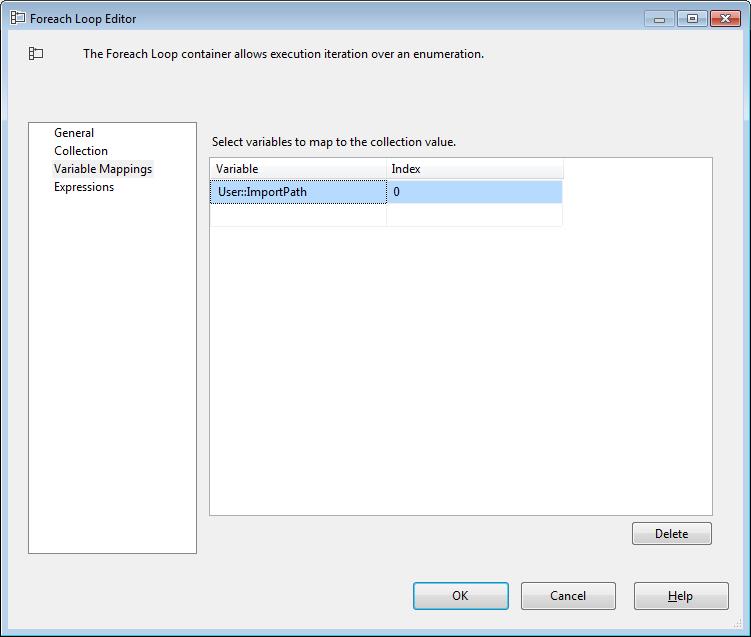
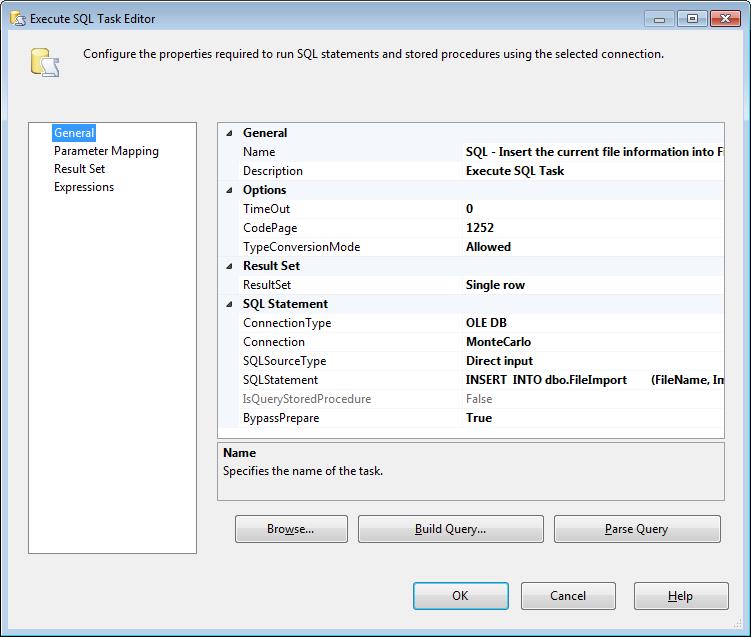
SQL – Insert the current file information into FileImport table
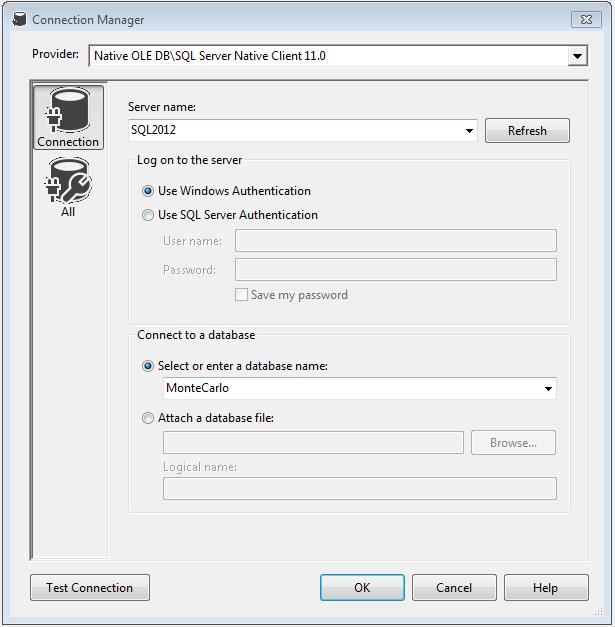
This Execute SQL Task will create a new entry into the FileImport Table and return the newly inserted identity value. We will need to set the Result Set to Single Row to capture the identity returned from the INSERT statement. Select the Connection type of OLE DB and the previously setup Connection. We will use a simple SQL Statement to Insert The file name and start date and return the identity.
INSERT INTO dbo.FileImport (FileName, ImportStartDate) VALUES (?, GETDATE()); SELECT FileImportID = @@IDENTITY; |
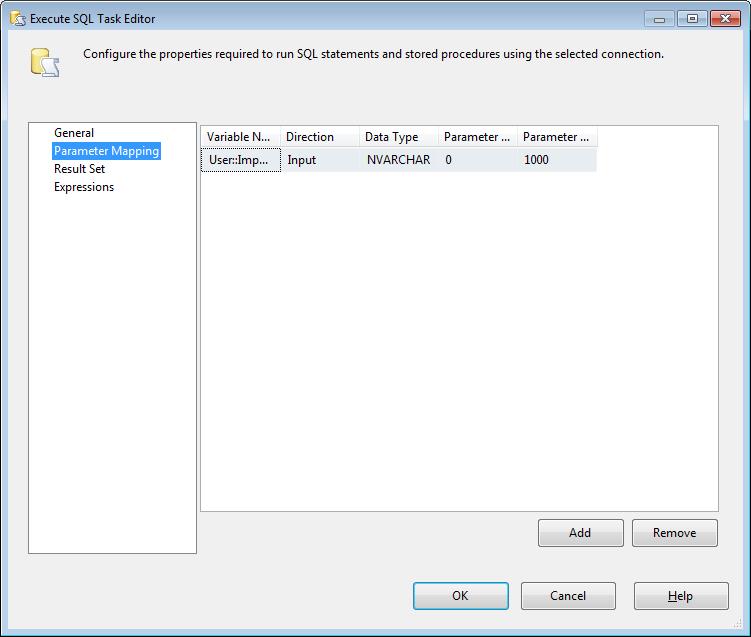
We are only using a single input parameter so we will need to add and map the ImportPath variable. Select the Data Type as NVARCHAR, Parameter Name = 0, and Parameter Size = 1000.
NOTE: The Parameter Names are a numerical ordering because we are using OLE DB Connections. For other types of connection types see Parameters and Return Codes in the Execute SQL Task, https://msdn.microsoft.com/en-us/library/cc280502.aspx
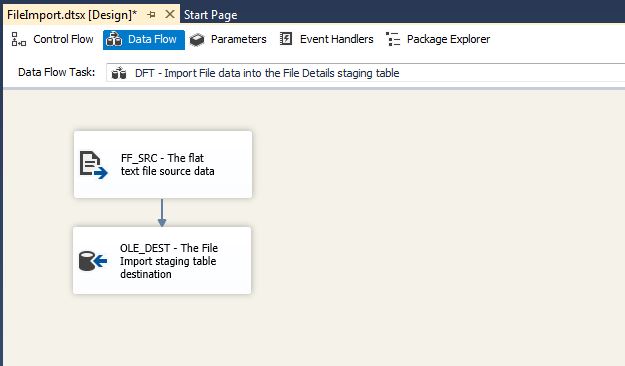
DFT – Import File data into the File Details staging table
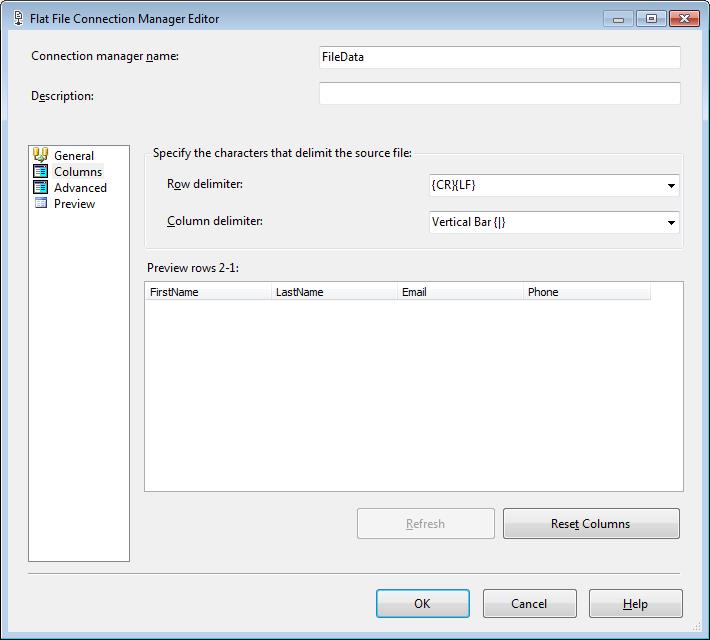
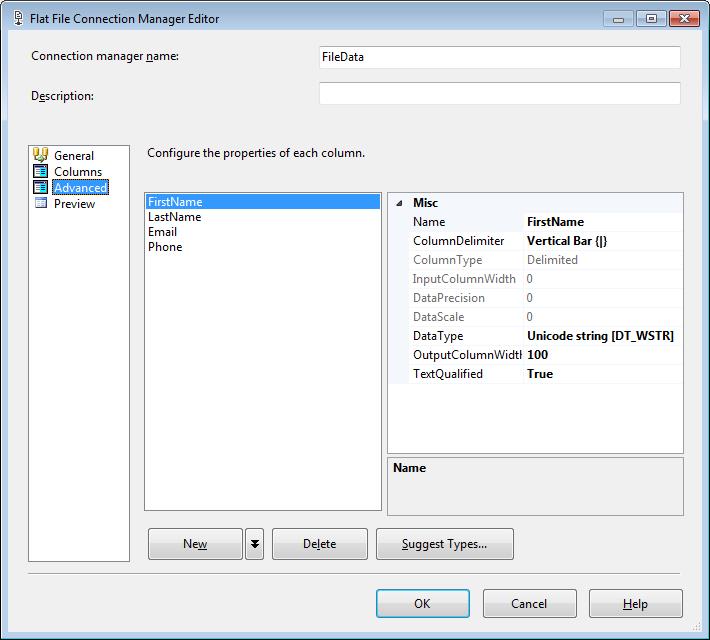
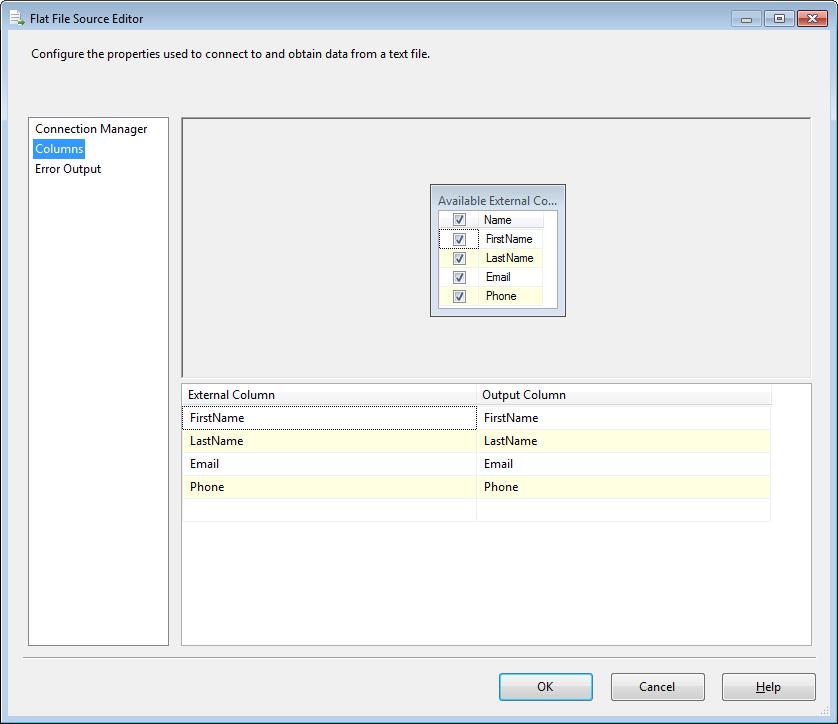
This Data Flow Task will be used to import each of the files into a staging table. In another Simple SSIS blog post the details for the file import process is documented.
Execution
After executing the File Loop SSIS package, all of the file paths that match the pattern FileData*.txt will have been placed in a temporary SSIS string variable, which can be used for other operations such as file imports. In my next Simple SSIS blog post I will review importing data from pipe delimited flat text files.